Here are their ethnic backgrounds and the results spreadsheet. Also relevant are the reference I admixture results.
If you can't see the interactive bar chart above, here's a static image.
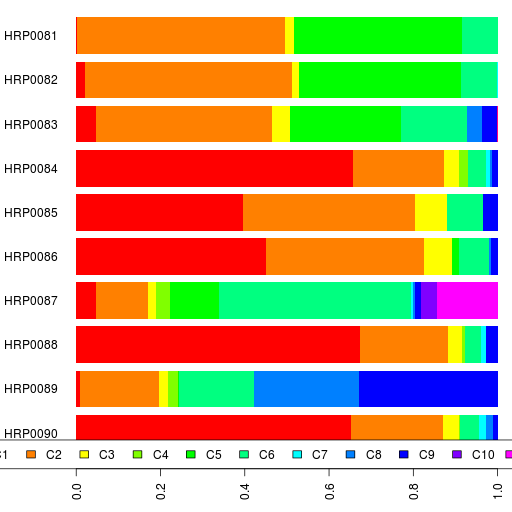
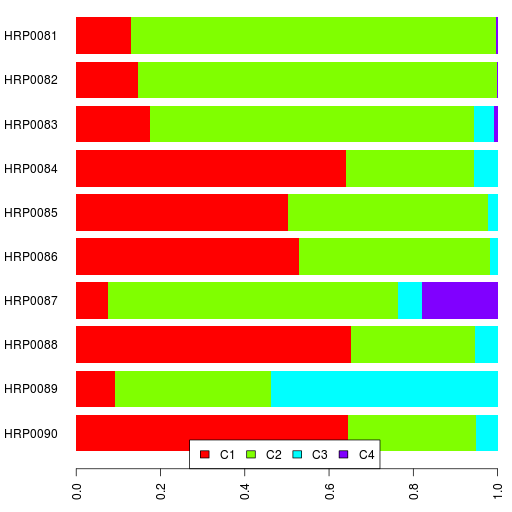
The two new Assyrians (HRP0081 & HRP0082) are pretty similar to the earlier Assyrian participant HRP0010.
HRP0087 is an interesting case with ancestry from France, Martinique, Madagascar and India. I can't be certain but the ratio of South Asian to Balochistan/Caucasus components seems to point in the direction of northern Indian ancestry. I definitely need to do a supervised admixture run for the mixed participants.
HRP0089 is Kazakh and has one-third Siberian component. That's higher than Uygurs (21%) and Uzbeks (23%) in my reference set. HRP0089 also has little bit more European component than the average Uygur or Uzbek in my reference.
PS. This was run using Admixture version 1.04.

















{kind=link}
{kind=link}
Recent Comments