It has been one year for the Harappa Ancestry Project. I announced it on January 17, 2011 and then moved it to its own domain on January 19.
It started out fast and furious with participants sending their data every day and I was blogging it multiple times a day. Now it has slowed down quite a bit with only one South Asian unrelated participant (not counting any Romany) in the last 2 months.
Speaking of participants, there have been a couple of complaints.
The decision to include non-South Asian participants from countries that do not neighbour the Subcontinent contradicts the Harappa Project's original inclusion criterion.
I concur with DMXX. While I'm certainly not anyone to tell Zack how to run his own show, I think the project is losing it's original focus. Accepting folks from West-Asia was also fine, given that South-Asians derive a lot of ancient ancestry from the area and thus may be deemed a secondary focus area. The same could also be said for those with partial Roma Gypsy ancestry. But, some of the runs seem to be almost entirely dominated by non-South Asian participants, who have absolutely no connection with the subcontinent. I can't help but ask on what basis these Brazilian, Belizean, Mexican, Hispanic, Somali, African-American and European participants were accepted into the project.
My approach has been to make it clear to any potential participants that my focus is on South Asia. Thus any Admixture components I have computed have been with a heavily South Asian dataset. Also, a number of PCA and clustering analyses that I do are at times limited to South Asians etc. On the other hand, I have accepted any participant who has asked to be included. I run a basic Admixture run for everyone which is a fairly automated process and sometimes include them in other analyses.
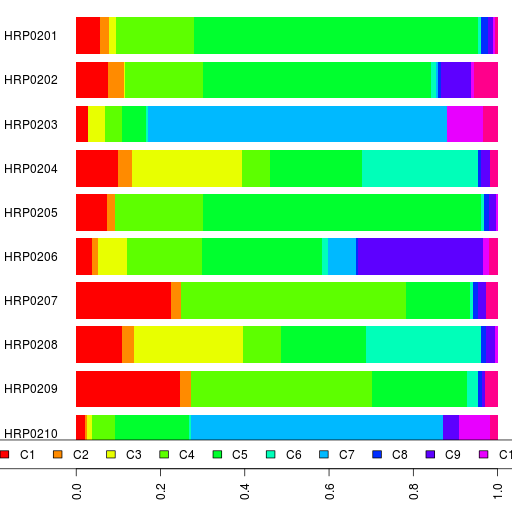
Let me illustrate with an example. I am working on a new Admixture calculator. For computing the components, I am using all the South Asian project participants in addition to reference datasets. I am going to select the data for that in such a way that we get Admixture components which gives us a better idea of South Asian genetic ancestry.
While participation in the project has slowed down, the research on South Asian genetics has picked up. We had the Metspalu et al paper and dataset. Also. 1000genomes is expected to release 400 South Asian samples (100 Lahori Punjabis, 100 Bangladeshis, 100 Sri Lankan Tamil and 100 Indian Telegu) over the summer.

























{kind=link}
{kind=link}
Recent Comments