From my Reference 3 dataset, I excluded the following populations for this set of admixture runs:
- Biaka Pygmy
- Mbuti Pymy
- San
- Bantu South Africa
- Hadza
- Chukchis
- Koryaks
- Colombian
- Dominican
- Ecuadorian
- Karitiana
- Maya
- Mexican
- Pima
- Puerto Rican
- Surui
- East Greenlanders
- West Greenlanders
- Australian aboriginals
- Melanesian
- Papuan
The San and Pygmy were removed since they are very distinct and take up clusters and the South African Bantu because they have significant admixture from the San. The Hadza seem to be a unique population too.
The Chukchis and Koryaks are Beringian populations from the Russian Far East which separate from the Siberian and Turco-Mongol groups at higher K's.
I also excluded all the American populations because our focus is on South Asia and environs. I have a few participants with Amerindian ancestry and I can always run their analyses with the full reference 3.
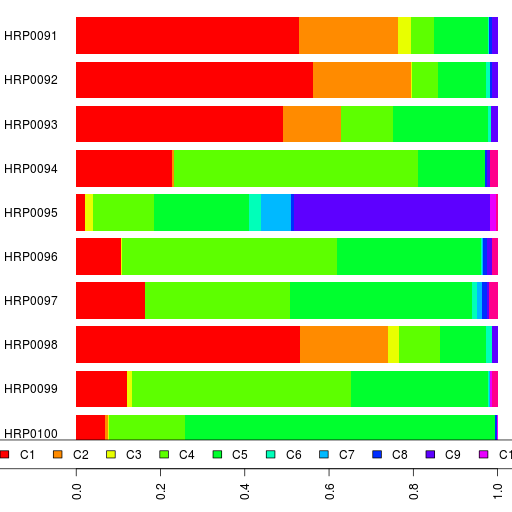
The Papuans and Melanesians take up 2 ancestral components in admixture at times and since admixture works well only for about K<12 or so, those are precious. Also, I originally thought that South Asians (specifically the ASI) might have some affinity with Papuans but that hasn't borne out. In addition to removing these populations, I reduced the number of samples of various groups (except South Asian ones) to 25 individuals so that admixture won't rely too heavily on any of those large groups (like the 161 Yoruba). In selecting individuals from these populations, I chose those closest to the median in terms of their admixture results. The admixture results of this dataset are in a spreadsheet as usual and the bar chart is below.
K=12 is the one with the lowest cross-validation error.
I am going to post another series of admixture runs tomorrow and then you guys can let me know which specific runs you like so we can switch to those for the project participants.
 K=11 C1 South Asia")








{kind=link}
Recent Comments