I ran PCA on the Reference I dataset which includes 2,654 samples from various populations.
Here are the top ten eigenvalues:
- 178.727040
- 118.884690
- 15.014072
- 9.346602
- 5.983225
- 5.140090
- 3.322723
- 2.739313
- 2.559640
- 2.475389
While the first two eigenvalues are much bigger than the rest, the first explains 6.82% of the variation and the second 4.54%, the Tracy-Widom stats show that about 70-something eeigenvectors are significant.
Here are the plots for the first 10 principal components. Remember that the 1st eigenvector is 1.5 times the 2nd.





Here is a 3-D PCA plot (hat tip: Doug McDonald) showing the first three eigenvectors. The plot is rotating about the 1st eigenvector which is vertical. Also, I have stretched the principal components based on the corresponding eigenvalues.
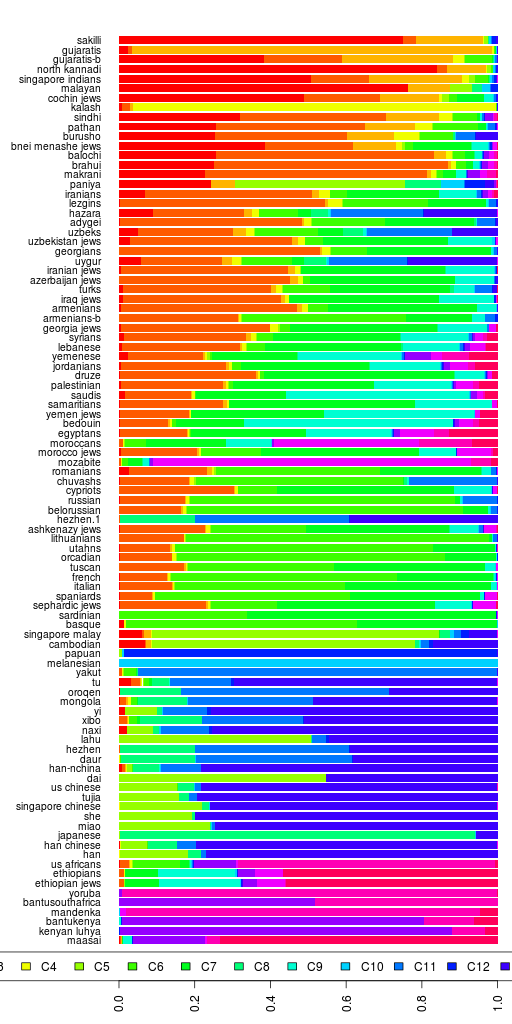
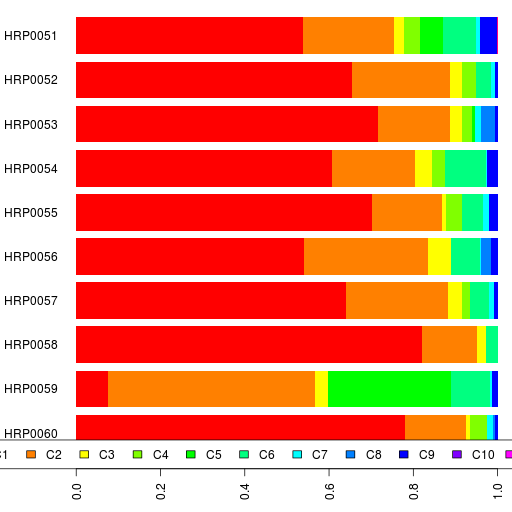
I also ran MClust on the PCA data and got 16 clusters. The results are in a spreadsheet. I am sure with more principal components than the 10 I used, I would be able to deduce finer population structure.
Note that African Americans cluster with East Africans in CL1. That's because African Americans have some European ancestry (20% on average) and that pulls them away from West Africans and towards Europeans. East Africans also lie in that direction, so they cluster together in a PCA. However, that doesn't mean that African Americans have East African ancestry. If you look at the Admixture results for African Americans, you see that their East African ancestry is negligible.





















{kind=link}
{kind=link}
Recent Comments