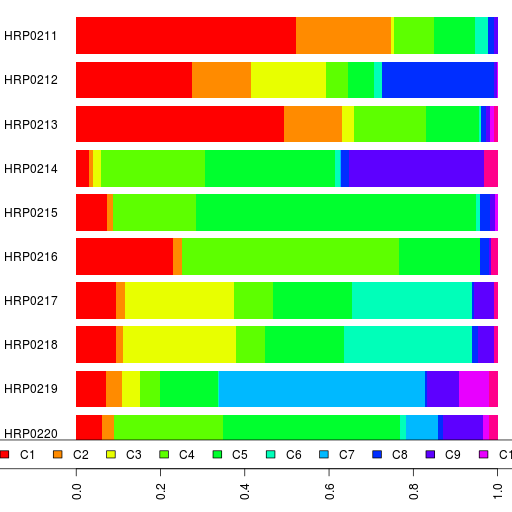
Here are the admixture results using Reference 3 for Harappa participants HRP0211 to HRP0220.
You can see the participant results in a spreadsheet as well as their ethnic breakdowns and the reference population results.
Here's our bar chart and table. Remember you can click on the legend or the table headers to sort.
If the above interactive charts are not working, here's a static bar graph.
Do note that small percentages for your results can be noise.
HRP0211 seems like a typical Tamil Brahmin.
HRP0212 is half-Fijian, half Indian/Pakistani/Afghan. It looks like his Fijian ancestry shows up as Papuan and East Asian mostly.
HRP0213 is a Gujarati Khoja whose results are not just different from the Gujarati Patels (Gujarati A) but also from HRP0130, a Gujarati Ganchi and HapMap Gujarati B.
HRP0216 is an Iraqi Assyrian and is a little more European than the other Assyrians. The Onge, Papuan and American are likely noise.
HRP0217 and HRP0218 are Kazakhs and fairly similar to the other Kazakhs in the project.
This will probably be the last admixture analysis using Reference 3.

{kind=link}
Thank you for posting these results, appreciated.
"This will probably be the last admixture analysis using Reference 3."
Zack, not to hurry you or anything of the sort, but, when do you expect that you will release your new ADMIXTURE analysis? Is there anything new we can expect from it, at least relative to the admixture exercises carried out by other projects (Dodecad/Eurogenes) and the ones here at HAP in the past?
I expect to have it ready by the end of the month.
Thanks, Zack. Also, HRP211 has ~3% Siberian admixture. What do you make of that?
I am not sure. HRP0211 is the only Tamil Brahmin to have Siberian component > 3%. In fact the only other South Indian Brahmin who has 3% is a Kannada Brahmin.
It's a little too big to be noise, but it's possible the standard error is more than 1%.
Since there are a few 1-2% results, I am running error estimation right now.
Is the South Asian I'm scoring ANI, ASI or a combination of both? I know this is probably a stupid question, but I was curious to know.
The Onge component is correlated with ASI. The South Asian component is mostly ANI.
Any plan for a calculator based on DIYDodecad? Comparing your dataset and components with another project like this would be interesting: http://dodecad.blogspot.com/2011/10/comparing-different-admixture-runs.html
I'll have the DIY calculator for the new admixture set I am working on. So, around early March.
You can download a "distance calculator" for the current version of the Harappa Ancestry Project here
http://www.forumbiodiversity.com/showthread.php?p=742434
or directly here:
https://docs.google.com/open?id=0BwVZU9mN1R6lYkhXdUZEMjlRSUdZOHZxYXoxalNaUQ
Looks interesting, though I don't have Excel on my home machine, so I haven't been able to test it.
Also, what's the difference between the normal and adjusted distance columns in the results?
I explained it here.
http://www.forumbiodiversity.com/showpost.php?p=571226&postcount=5
The adjustment is to address the relation of the different components to each other based on the Fst divergences you provided here:
http://www.harappadna.org/2011/04/reference-3-admixture-k11/
You can download a "Oracle mixmode calculator" for the current version of the Harappa Ancestry Project here
http://www.forumbiodiversity.com/showthread.php?p=753319#post753319
or directly here:
https://docs.google.com/open?id=0BwVZU9mN1R6lQy0wTHdQeFZScGVTc2g5akh4MHZzUQ
Zack, what proof do you have that the Gujarati_a (Hapmap) are Patels? And if so: are they Hindu or Muslim Patels? I'd like to see substantiated evidence for this claim.
Secondly, the reason that the Gujarati (Harappa) participants differ in their results from the Gujarati Hapmap is quite simple. Allow me to explain:
1. The Gujarati (Harappa) participants have diverse origins.
One is a Shia Khoja, another a Ghanchi (teli found throughout Gujarat and Rajasthan), another a Gujarati Muslim Patel with some foreign admixture, and the last a Vaniya (most likely Hindu) = all of these are different castes, and so they should differ in their results from one another. That is totally expected. There is marked caste organization in Gujarat where caste identity is still extremely important to Hindus (but not as much important to minorities), and so results will be all over the place.
2. The Hapmap samples do NOT represent the vast majority of Gujaratis because the samples were taken ONLY from Houston Texas (America) thus there is an absolute bias going on here. Gujarati_a are an outgroup to everyone else (including other Gujaratis) and form a tight cluster of closely related individuals because they are from the same jati. This is because Gujaratis who emigrate to America follow a pattern of chain migration which results in their entire extended families being concentrated in their locality or towns. The scientists who collated Gujarati Hapmap data should have known better and taken samples from all over North America because Hindus have hundreds of various Samaj associations that are quite strict about not mixing with Hindus from another Samaj.
3. The Gujarati_b Hapmaps (loose cluster) are a slightly better representation of Gujaratis but which jatis comprise this group? And where's the substantiated evidence for the claim?
4. Where are the Gujarati Brahmins? Why are they not being represented here like they are with everyone else?
Now keep in mind that there are tens of hundreds of jatis in Gujarat, and it gets even more complicated than that because the Hindus from one jati do not mix with the Hindus from other jatis, and ALL of them consider it taboo to mix with Gujarati Muslims and/or outsiders (unless the families are Westernized, in which case they make special concessions for Europeans).
Then there are are other minorities such as Christians, Parsi and Sikhs, as well as Sindhi Hindus.
The Gujarati Muslims form approx 10% of Gujarat's demographics and have their own Jamaats. This is why I said Gujarati Muslims deserve their own separate category on Harappa much like how you have separated Bihari Hindus and Bihari Muslims. The Gujarati Khojas are Nizari Ismaili Shias, many of whom moved to East Africa along with the Aga Khani Persians and adopted the larger Twelver branch of Shi'a Islam (most famous adherent being Mohammed Ali Jinnah). As such, there's a large vocal Khoja diaspora who are found in East Africa, North America and Europe. But aside from there, are Bohras, Memons, Kutchis, Chhipas, Surtis and so many other Muslim Jamaats.
I have no proof. It's just a conjecture, based on how closely related the Gujarati-a are to the Patel participants of my project and also how Patels are one of the major immigrant groups. That is why I haven't named them gujarati-patel but called them gujarati-a.
I rely on academic datasets that researchers are kind to share with me as well as the South Asians who send me their data. No Brahmins from Gujarat have submitted their data yet. If you know of any who have tested with 23andme, FTDNA Family Finder or Geno2, please convince them to participate.
It's a fairly accurate conjecture based on the relatedness of the Gujarati A's to the individual Patel participants like you mentioned, Zack. However, it makes even more sense with anyone familiar with Houston and it's large South Asian population. While there are various Gujarati communities there including Brahmins, the vast majority are Hindu Patels. Still, there is always a possiblity of them being Bohras or some other community.
Razib commented on them before. I think his Gujarati A and B's are reversed though.
http://sepiamutiny.com/blog/2011/04/29/structure_with/
In regards to the Gujarati B samples, it was assumed they were likely upper castes based on their results in comparison to the Patels. Whether they were Brahmins, Rajputs, etc. is unknown however.
@LRG
There's no proof that Gujarati_ b are all Brahmin "upper-castes" or otherwise from the same clan. This is wild speculation on your part and sounds more like nationalist nonsense to me. The cluster is a loose one, indicating that there are most likely individuals from several various backgrounds there - some of them could be Muslims for all we know. I know Gujarati Hindu/Christian/Muslim Rajputs, Shia Ismaili Khojas, Zoroastrian Parsi, Bohra, Chhipas, Memons, and a multitude of other Gujarati communities in America. Funny thing is you say you are familiar with the Houston Gujjus but you don't know that! Jeez...
There's no reason to believe that Gujarati_b are all Brahmins unless you can support that with a source from Hapmap. If you can't do that then I'm not buying it - simple. Burden of proof is on the one making the outrageous proposition - not the one seeking the proof.
I know everything about Razib so no need to point me toward the links. While you admit that the "vast majority" in Houston are Hindu Patels and attempt to link them with the Gujarati_a sample, you still go out of your way to admit that you can't be "sure" because the samples could be from other communities, which exposes the cracks in your weak argument.
Also I personally know the dude who made the same argument as you (ie. that Gujarati_b could be Brahmins) on an anthropology forum that you, I and several others frequently visited before its fated extinction, and so by default I know exactly who you are, LRG.
I don't know whether the Gujarati B samples are all upper castes. I said it was assumed by others (either here or Razib's blog) that they were likely upper castes (Brahmins, Rajputs, etc.) based on their results in comparison to the Gujarati A cluster who are often speculated to be Hindu Patels based on what Zack and Razib have suggested in the past. There very well could be some Patels and middle class communities in the Gujarati B cluster and there likely are.
I'm not sure why but you've quickly jumped the gun and implied that I've suggested that the Gujarati B's are all Brahmin "upper castes." In fact, it was someone else that originally suggested that they could be potentially upper caste either on here or on Razib Khans' sepia mutiny blog. It is not wild speculation on my part because I've never declared my personal opinion on who the Gujarati B cluster definitely are. Although, I personally feel they are a mix of middle and upper class individuals but that is just speculation on my part.
It's great that you know the multitude of Gujarati American communities but I have made zero definite conclusions on the Gujarati B cluster as I've already mentioned. In fact, I'm mostly just supporting the potential possiblity that the Gujarati A cluster is likely Hindu Patels.
Cracks in my weak argument? I'm not making any argument that the Gujarat A samples are definitely 100% Patels. I'm just suggesting that it is a high possibility based on what Zack and Razib have suggested and the fact that Houston has a large Hindu Patel community. However, Razib has also suggested they might be Bohras and I agree that it's always possible they aren't Patels.
Lastly, I don't frequent any anthro forums nor do I have any idea whom you are or whom you think I am. I've simply been following the Harappa Ancestry Project from time to time along with Razib's blogs in the past. I've also never made the argument that the Gujarati B's are all Brahmins for sure.
Gujarati-b are fairly loosely clustered with differing closeness to other South Asian groups. Therefore, they are likely from several Gujarati communities.
Agreed. They are likely a mix of various Gujartai communities with some upper castes and middle classes likely in the mix.